Slim Framework
微型Restful框架 传送门》》》
微型Restful框架 传送门》》》
LXC:Linux 容器工具 容器可以提供轻量级的虚拟化,以便隔离进程和资源,而且不需要提供指令解释机制以及全虚拟化的其他复杂性。本文循序渐进地介绍容器工具 Linux® Containers(LXC)。作者在文中演示如何设置和使用它们。
错误如下: You don’t have permission to access / … 我启用了 http-vhosts.conf DocumentRoot 设在了我的home目录里具体目录为 /User/seven/www, 属主是seven这个用户 我发现os x apache 的用户是 _www 但是系统里没有这个用户的信息,一番research后找到了解决方案。 到/etc/apache2/users 下创建文件 Seven.conf [text] <Directory “/Users/seven/www/”> Options Indexes MultiViews AllowOverride All Order allow,deny Allow from all [/text] 重启apache就OK了 [bash] apachectl restart [/bash]

扫一扫
这个组件可以解决圆角和阴影在各浏览器中的兼容问题 猛击这里
TFS(Taobao !FileSystem)是一个高可扩展、高可用、高性能、面向互联网服务的分布式文件系统,主要针对海量的非结构化数据,它构筑在普通的Linux机器 集群上,可为外部提供高可靠和高并发的存储访问。TFS为淘宝提供海量小文件存储,通常文件大小不超过1M,满足了淘宝对小文件存储的需求,被广泛地应用 在淘宝各项应用中。它采用了HA架构和平滑扩容,保证了整个文件系统的可用性和扩展性。同时扁平化的数据组织结构,可将文件名映射到文件的物理地址,简化 了文件的访问流程,一定程度上为TFS提供了良好的读写性能。
一个TFS集群由两个!NameServer节点(一主一备)和多个!DataServer节点组成。这些服务程序都是作为一个用户级的程序运行在普通Linux机器上的。 在TFS中,将大量的小文件(实际数据文件)合并成为一个大文件,这个大文件称为块(Block), 每个Block拥有在集群内唯一的编号(Block Id), Block Id在!NameServer在创建Block的时候分配, !NameServer维护block与!DataServer的关系。Block中的实际数据都存储在!DataServer上。而一 台!DataServer服务器一般会有多个独立!DataServer进程存在,每个进程负责管理一个挂载点,这个挂载点一般是一个独立磁盘上的文件目 录,以降低单个磁盘损坏带来的影响。 !NameServer主要功能是: 管理维护Block和!DataServer相关信息,包括!DataServer加入,退出, 心跳信息, block和!DataServer的对应关系建立,解除。正常情况下,一个块会在!DataServer上存在, 主!NameServer负责Block的创建,删除,复制,均衡,整理, !NameServer不负责实际数据的读写,实际数据的读写由!DataServer完成。 !DataServer主要功能是: 负责实际数据的存储和读写。 同时为了考虑容灾,!NameServer采用了HA结构,即两台机器互为热备,同时运行,一台为主,一台为备,主机绑定到对外vip,提供服务;当主机 器宕机后,迅速将vip绑定至备份!NameServer,将其切换为主机,对外提供服务。图中的HeartAgent就完成了此功能。 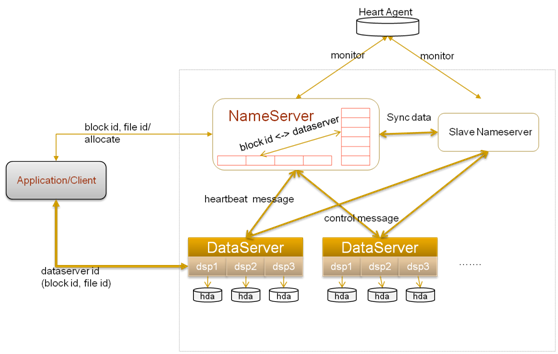 TFS的块大小可以通过配置项来决定,通常使用的块大小为64M。TFS的设计目标是海量小文件的存储,所以每个块中会存储许多不同的小文 件。!DataServer进程会给Block中的每个文件分配一个ID(File ID,该ID在每个Block中唯一),并将每个文件在Block中的信息存放在和Block对应的Index文件中。这个Index文件一般都会全部 load在内存,除非出现!DataServer服务器内存和集群中所存放文件平均大小不匹配的情况。 另外,还可以部署一个对等的TFS集群,作为当前集群的辅集群。辅集群不提供来自应用的写入,只接受来自主集群的写入。当前主集群的每个数据变更操作都会重放至辅集群。辅集群也可以提供对外的读,并且在主集群出现故障的时候,可以接管主集群的工作。
TFS的块大小可以通过配置项来决定,通常使用的块大小为64M。TFS的设计目标是海量小文件的存储,所以每个块中会存储许多不同的小文 件。!DataServer进程会给Block中的每个文件分配一个ID(File ID,该ID在每个Block中唯一),并将每个文件在Block中的信息存放在和Block对应的Index文件中。这个Index文件一般都会全部 load在内存,除非出现!DataServer服务器内存和集群中所存放文件平均大小不匹配的情况。 另外,还可以部署一个对等的TFS集群,作为当前集群的辅集群。辅集群不提供来自应用的写入,只接受来自主集群的写入。当前主集群的每个数据变更操作都会重放至辅集群。辅集群也可以提供对外的读,并且在主集群出现故障的时候,可以接管主集群的工作。
原有TFS集群运行一定时间后,集群容量不足,此时需要对TFS集群扩容。由于DataServer与NameServer之间使用心跳机制通信,如果系 统扩容,只需要将相应数量的新!DataServer服务器部署好应用程序后启动即可。这些!DataServer服务器会向!NameServer进行 心跳汇报。!NameServer会根据!DataServer容量的比率和!DataServer的负载决定新数据写往哪台!DataServer的服 务器。根据写入策略,容量较小,负载较轻的服务器新数据写入的概率会比较高。同时,在集群负载比较轻的时候,!NameServer会 对!DataServer上的Block进行均衡,使所有!DataServer的容量尽早达到均衡。 进行均衡计划时,首先计算每台机器应拥有的blocks平均数量,然后将机器划分为两堆,一堆是超过平均数量的,作为移动源;一类是低于平均数量的,作为移动目的。 移动目的的选择:首先一个block的移动的源和目的,应该保持在同一网段内,也就是要与另外的block不同网段;另外,在作为目的的一定机器内,优先选择同机器的源到目的之间移动,也就是同台!DataServer服务器中的不同!DataServer进程。 当有服务器故障或者下线退出时(单个集群内的不同网段机器不能同时退出),不影响TFS的服务。此时!NameServer会检测到备份数减少的Block,对这些Block重新进行数据复制。 在创建复制计划时,一次要复制多个block, 每个block的复制源和目的都要尽可能的不同,并且保证每个block在不同的子网段内。因此采用轮换选择(roundrobin)算法,并结合加权平均。 由于DataServer之间的通信是主要发生在数据写入转发的时候和数据复制的时候,集群扩容基本没有影响。假设一个Block为64M,数量级为 1PB。那么NameServer上会有 1 * 1024 * 1024 * 1024 / 64 = 16.7M个block。假设每个Block的元数据大小为0.1K,则占用内存不到2G。
在TFS中,将大量的小文件(实际用户文件)合并成为一个大文件,这个大文件称为块(Block)。TFS以Block的方式组织文件的存储。每一个 Block在整个集群内拥有唯一的编号,这个编号是由NameServer进行分配的,而DataServer上实际存储了该Block。 在!NameServer节点中存储了所有的Block的信息,一个Block存储于多个!DataServer中以保证数据的冗余。对于数据读写请求, 均先由!NameServer选择合适的!DataServer节点返回给客户端,再在对应的!DataServer节点上进行数据操 作。!NameServer需要维护Block信息列表,以及Block与!DataServer之间的映射关系,其存储的元数据结构如下: 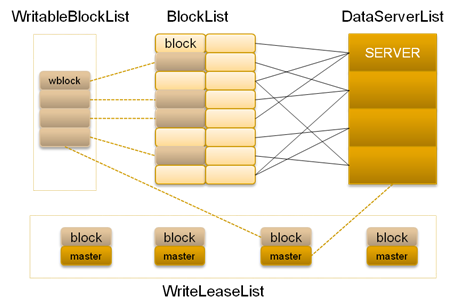 在!DataServer节点上,在挂载目录上会有很多物理块,物理块以文件的形式存在磁盘上,并在!DataServer部署前预先分配,以保证后续的 访问速度和减少碎片产生。为了满足这个特性,!DataServer现一般在EXT4文件系统上运行。物理块分为主块和扩展块,一般主块的大小会远大于扩 展块,使用扩展块是为了满足文件更新操作时文件大小的变化。每个Block在文件系统上以“主块+扩展块”的方式存储。每一个Block可能对应于多个物 理块,其中包括一个主块,多个扩展块。 在DataServer端,每个Block可能会有多个实际的物理文件组成:一个主Physical Block文件,N个扩展Physical Block文件和一个与该Block对应的索引文件。Block中的每个小文件会用一个block内唯一的fileid来标识。!DataServer会 在启动的时候把自身所拥有的Block和对应的Index加载进来。
在!DataServer节点上,在挂载目录上会有很多物理块,物理块以文件的形式存在磁盘上,并在!DataServer部署前预先分配,以保证后续的 访问速度和减少碎片产生。为了满足这个特性,!DataServer现一般在EXT4文件系统上运行。物理块分为主块和扩展块,一般主块的大小会远大于扩 展块,使用扩展块是为了满足文件更新操作时文件大小的变化。每个Block在文件系统上以“主块+扩展块”的方式存储。每一个Block可能对应于多个物 理块,其中包括一个主块,多个扩展块。 在DataServer端,每个Block可能会有多个实际的物理文件组成:一个主Physical Block文件,N个扩展Physical Block文件和一个与该Block对应的索引文件。Block中的每个小文件会用一个block内唯一的fileid来标识。!DataServer会 在启动的时候把自身所拥有的Block和对应的Index加载进来。
TFS可以配置主辅集群,一般主辅集群会存放在两个不同的机房。主集群提供所有功能,辅集群只提供读。主集群会把所有操作重放到辅集群。这样既提供了负载均衡,又可以在主集群机房出现异常的情况不会中断服务或者丢失数据。
Namserver主要管理了!DataServer和Block之间的关系。如每个!DataServer拥有哪些Block,每个Block存放在哪 些!DataServer上等。同时,!NameServer采用了HA结构,一主一备,主NameServer上的操作会重放至备 NameServer。如果主NameServer出现问题,可以实时切换到备NameServer。 另外!NameServer和!DataServer之间也会有定时的heartbeat,!DataServer会把自己拥有的Block发送给!NameServer。!NameServer会根据这些信息重建!DataServer和Block的关系。
TFS采用Block存储多份的方式来实现!DataServer的容错。每一个Block会在TFS中存在多份,一般为3份,并且分布在不同网段的不 同!DataServer上。对于每一个写入请求,必须在所有的Block写入成功才算成功。当出现磁盘损坏!DataServer宕机的时候,TFS启 动复制流程,把备份数未达到最小备份数的Block尽快复制到其他DataServer上去。 TFS对每一个文件会记录校验crc,当客户端发现crc和文件内容不匹配时,会自动切换到一个好的block上读取。此后客户端将会实现自动修复单个文 件损坏的情况。
对于同一个文件来说,多个用户可以并发读。 现有TFS并不支持并发写一个文件。一个文件只会有一个用户在写。这在TFS的设计里面对应着是一个block同时只能有一个写或者更新操作。
TFS的文件名由块号和文件号通过某种对应关系组成,最大长度为18字节。文件名固定以T开始,第二字节为该集群的编号(可以在配置项中指定,取值范围 1~9)。余下的字节由Block ID和File ID通过一定的编码方式得到。文件名由客户端程序进行编码和解码,它映射方式如下图: 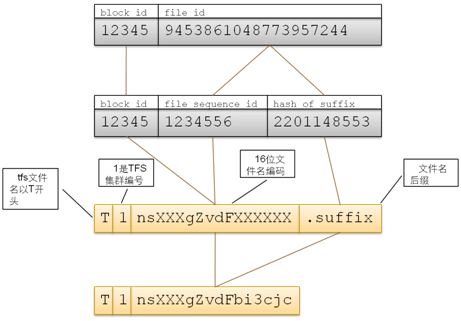 TFS客户程序在读文件的时候通过将文件名转换为BlockID和FileID信息,然后可以在!NameServer取得该块所 在!DataServer信息(如果客户端有该Block与!DataServere的缓存,则直接从缓存中取),然后与!DataServer进行读取 操作。
TFS客户程序在读文件的时候通过将文件名转换为BlockID和FileID信息,然后可以在!NameServer取得该块所 在!DataServer信息(如果客户端有该Block与!DataServere的缓存,则直接从缓存中取),然后与!DataServer进行读取 操作。
【测试机软件情况描述】 (1) Red Hat Enterprise Linux AS release 4 (Nahant Update 8) (2) gcc (GCC) 3.4.6 20060404 (Red Hat 3.4.6-11) (3) 部署了TFS客户端程序 【服务器软件情况描述】 (1) Red Hat Enterprise Linux Server release 5.4 (Tikanga) (2) gcc (GCC) 3.4.6 20060404 (Red Hat 3.4.6-9) (3) 部署了2台!DataServer程序。 【服务器软件情况描述】 (1) Red Hat Enterprise Linux Server release 5.4 (Tikanga) (2) gcc (GCC) 4.1.2 20080704 (Red Hat 4.1.2-46) (3) 部署了2台!NameServer(HA)程序。
【测试机硬件情况描述】 (1) 一枚八核Intel® Xeon® CPU E5520 @ 2.27GHz (2) 内存总数8299424 kB 【服务器硬件情况描述】cpu/memory等 (1) 一枚八核Intel® Xeon® CPU E5520 @ 2.27GHz (2) 内存总数8165616 kB 随机读取1K~50K大小的文件性能 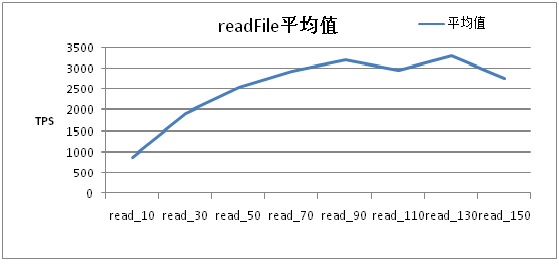 Read的TPS随着线程数的增加而增加,增长逐渐趋缓,到90线程的时候达到第一个高峰,此时再增加读线程,则TPS不再稳定增长。 随机写入1K~50K大小的文件
Read的TPS随着线程数的增加而增加,增长逐渐趋缓,到90线程的时候达到第一个高峰,此时再增加读线程,则TPS不再稳定增长。 随机写入1K~50K大小的文件 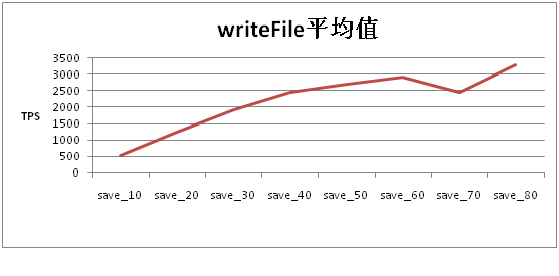 Write的TPS在线程数60左右达到高峰,此时再增加写入线程,TPS不再稳定增长。 在不同线程写压力下的读文件性能
Write的TPS在线程数60左右达到高峰,此时再增加写入线程,TPS不再稳定增长。 在不同线程写压力下的读文件性能 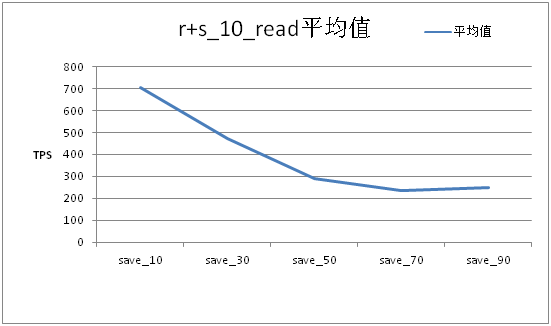
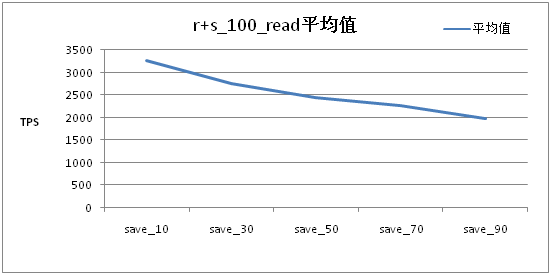 可以看出随着写压力的增加,读文件的TPS会大幅下滑。当写压力达到一定程度时读文件TPS趋缓。 同时,对平均大小为20K的文件进行了测试,测试中读:写:更新:删除操作的比率为100:18:1:1时,在!DataServer服务器磁盘util访问达到80%以上时,响应时间如下:
可以看出随着写压力的增加,读文件的TPS会大幅下滑。当写压力达到一定程度时读文件TPS趋缓。 同时,对平均大小为20K的文件进行了测试,测试中读:写:更新:删除操作的比率为100:18:1:1时,在!DataServer服务器磁盘util访问达到80%以上时,响应时间如下:
TYPE
SUCCCOUNT
FAILCOUNT
AVG(us)
MIN(us)
MAX(us)
read
100000
0
20886
925
1170418
write
18000
0
17192
2495
1660686
update
1000
0
48489
5755
1205119
delete
1000
0
14221
382
591651
TYPE:操作类型 SUCCCOUNT:成功个数 FAILCOUNT:失败个数 AVG:平均响应时间 MIN:最短响应时间 MAX: 最大响应时间
[code language=“php”] function microtime_float() { list ( $usec, $sec ) = explode ( " ", microtime () ); return (( float ) $usec + ( float ) $sec); } function cmp($a, $b) { if ($a == $b) { return 0; } return ($a < $b) ? - 1 : 1; } /** * ******************************************** */ $time_start = microtime_float (); $ss = array (); for($j = 0; $j < 3000; ++ $j) { $n = $j + rand ( 0, 999999 ) / 0.000001; array_push ( $ss, $n ); } usort ( $ss, “cmp” ); $tim = microtime_float () - $time_start; print_r ( $ss ); echo “Did nothing in " . sprintf ( “%.2f”, $tim ) . " seconds\n”; [/code]
synergy 是一个键盘鼠标共享软件,通过网络让不同主机(跨平台, linux / win / mac)共享一套键盘鼠标。它还是免费的! 马上去下载
TCP_HIT A valid copy of the requested object was in the cache. TCP_MISS The requested object was not in the cache. TCP_REFRESH_HIT The requested object was cached but STALE. The IMS query for the object resulted in “304 not modified”. TCP_REF_FAIL_HIT The requested object was cached but STALE. The IMS query failed and the stale object was delivered. TCP_REFRESH_MISS The requested object was cached but STALE. The IMS query returned the new content. TCP_CLIENT_REFRESH_MISS The client issued a “no-cache” pragma, or some analogous cache control command along with the request. Thus, the cache has to refetch the object. TCP_IMS_HIT The client issued an IMS request for an object which was in the cache and fresh. TCP_SWAPFAIL_MISS The object was believed to be in the cache, but could not be accessed. TCP_NEGATIVE_HIT Request for a negatively cached object, e.g. “404 not found”, for which the cache believes to know that it is inaccessible. Also refer to the explainations for negative_ttl in your squid.conf file. TCP_MEM_HIT A valid copy of the requested object was in the cache and it was in memory, thus avoiding disk accesses. TCP_DENIED Access was denied for this request. TCP_OFFLINE_HIT The requested object was retrieved from the cache during offline mode. The offline mode never validates any object, see offline_mode in squid.conf file. UDP_HIT A valid copy of the requested object was in the cache. UDP_MISS The requested object is not in this cache. UDP_DENIED Access was denied for this request. UDP_INVALID An invalid request was received. UDP_MISS_NOFETCH During “-Y” startup, or during frequent failures, a cache in hit only mode will return either UDP_HIT or this code. Neighbours will thus only fetch hits. NONE Seen with errors and cachemgr requests. The following codes are no longer available in Squid-2: ERR_* Errors are now contained in the status code. TCP_CLIENT_REFRESH See: TCP_CLIENT_REFRESH_MISS. TCP_SWAPFAIL See: TCP_SWAPFAIL_MISS. TCP_IMS_MISS Deleted, TCP_IMS_HIT used instead. UDP_HIT_OBJ Hit objects are no longer available. UDP_RELOADING See: UDP_MISS_NOFETCH.